








































































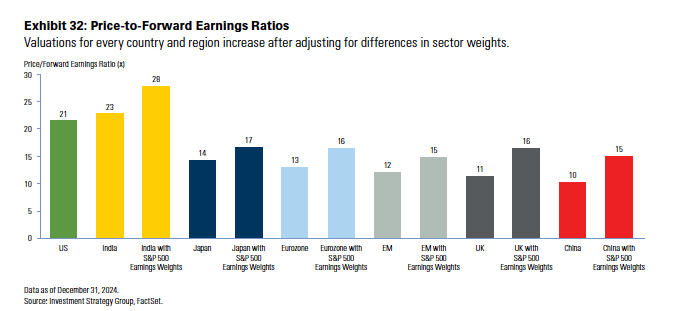

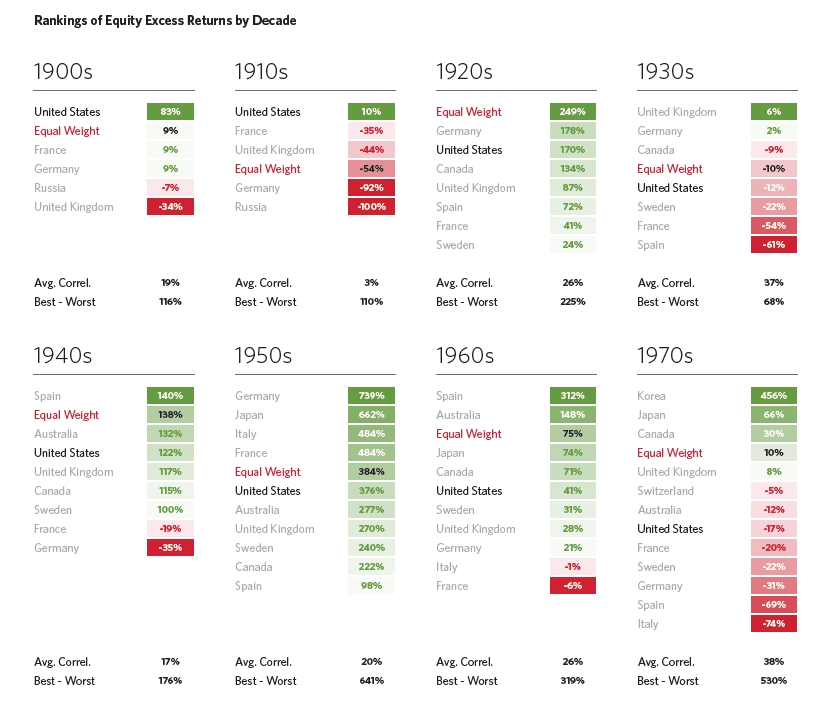





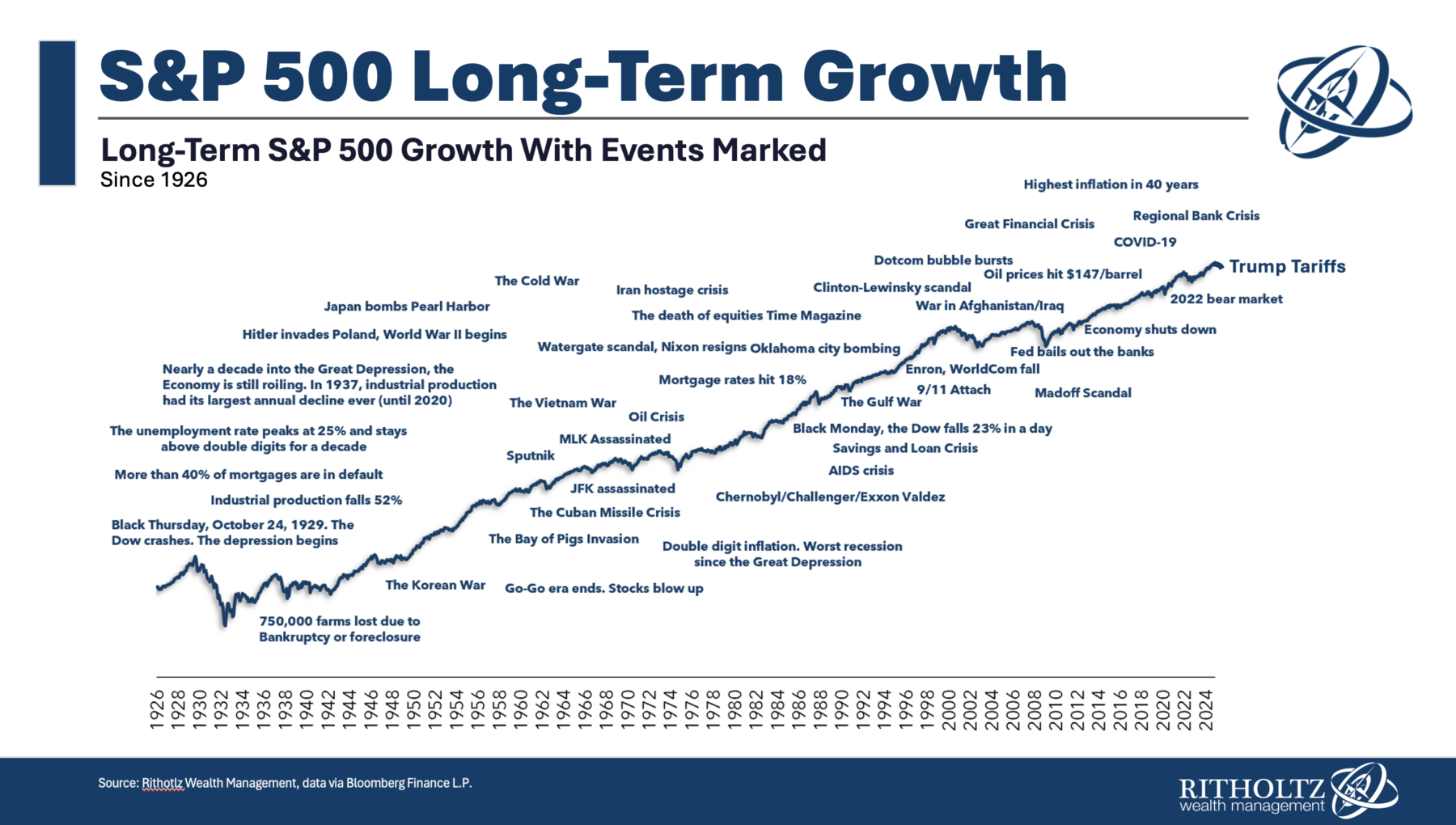









































































OpenAI’s DeepResearch can complete 26% of ‘Humanity’s Last Exam’ — a benchmark for the frontier of human knowledge
OpenAI’s o1 and DeepSeek’s R1 models, which previously sat atop the leaderboard, could only get through roughly 9% of the exam.

OpenAI’s o1 and DeepSeek’s R1 models, which previously sat atop the leaderboard, could only get through roughly 9% of the exam. Read More
