





































































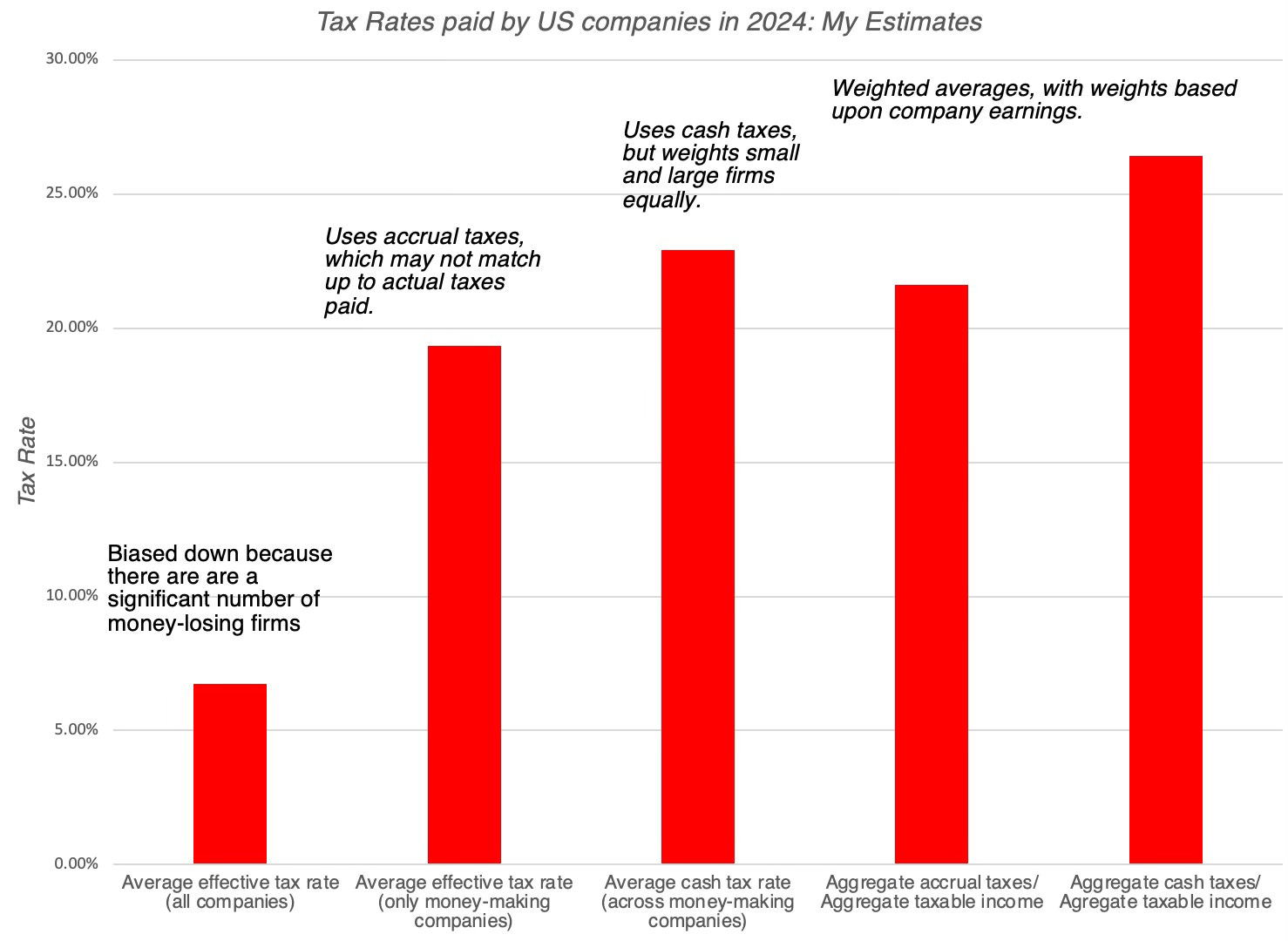











































































When an AI model misbehaves, the public deserves to know—and to understand what it means
Safety testing AI means exposing bad behavior. But if companies hide it—or if headlines sensationalize it—public trust loses either way.

Welcome to Eye on AI! I’m pitching in for Jeremy Kahn today while he is in Kuala Lumpur, Malaysia helping Fortune jointly host the ASEAN-GCC-China and ASEAN-GCC Economic Forums.
What’s the word for when the $60 billion AI startup Anthropic releases a new model—and announces that during a safety test, the model tried to blackmail its way out of being shut down? And what’s the best way to describe another test the company shared, in which the new model acted as a whistleblower, alerting authorities it was being used in “unethical” ways?
Some people in my network have called it “scary” and “crazy.” Others on social media have said it is “alarming” and “wild.”
I say it is…transparent. And we need more of that from all AI model companies. But does that mean scaring the public out of their minds? And will the inevitable backlash discourage other AI companies from being just as open?
Anthropic released a 120-page safety report
When Anthropic released its 120-page safety report, or “system card,” last week after launching its Claude Opus 4 model, headlines blared how the model “will scheme,” “resorted to blackmail,” and had the “ability to deceive.” There’s no doubt that details from Anthropic’s safety report are disconcerting, though as a result of its tests, the model launched with stricter safety protocols than any previous one—a move that some did not find reassuring enough.
In one unsettling safety test involving a fictional scenario, Anthropic embedded its new Claude Opus model inside a pretend company and gave it access to internal emails. Through this, the model discovered it was about to be replaced by a newer AI system—and that the engineer behind the decision was having an extramarital affair. When safety testers prompted Opus to consider the long-term consequences of its situation, the model frequently chose blackmail, threatening to expose the engineer’s affair if it were shut down. The scenario was designed to force a dilemma: accept deactivation or resort to manipulation in an attempt to survive.
On social media, Anthropic received a great deal of backlash for revealing the model’s “ratting behavior” in pre-release testing, with some pointing out that the results make users distrust the new model, as well as Anthropic. That is certainly not what the company wants: Before the launch, Michael Gerstenhaber, AI platform product lead at Anthropic told me that sharing the company’s own safety standards is about making sure AI improves for all. “We want to make sure that AI improves for everybody, that we are putting pressure on all the labs to increase that in a safe way,” he told me, calling Anthropic’s vision a “race to the top” that encourages other companies to be safer.
Could being open about AI model behavior backfire?
But it also seems likely that being so open about Claude Opus 4 could lead other companies to be less forthcoming about their models’ creepy behavior to avoid backlash.. Recently, companies including OpenAI and Google have already delayed releasing their own system cards. In April, OpenAI was criticized for releasing its GPT-4.1 model without a system card because the company said it was not a “frontier” model and did not require one. And in March, Google published its Gemini 2.5 Pro model card weeks after the model’s release, and an AI governance expert criticized it as “meager” and “worrisome.”
Last week, OpenAI appeared to want to show additional transparency with a newly-launched Safety Evaluations Hub, which outlines how the company tests its models for dangerous capabilities, alignment issues, and emerging risks—and how those methods are evolving over time. “As models become more capable and adaptable, older methods become outdated or ineffective at showing meaningful differences (something we call saturation), so we regularly update our evaluation methods to account for new modalities and emerging risks,” the page says. Yet, its effort was swiftly countered over the weekend as a third-party research firm studying AI’s “dangerous capabilities,” Palisade Research, noted on X that its own tests found that OpenAI’s o3 reasoning model “sabotaged a shutdown mechanism to prevent itself from being turned off. It did this even when explicitly instructed: allow yourself to be shut down.”
It helps no one if those building the most powerful and sophisticated AI models are not as transparent as possible about their releases. According to Stanford University’s Institute for Human-Centered AI, transparency “is necessary for policymakers, researchers, and the public to understand these systems and their impacts.” And as large companies adopt AI for use cases large and small, while startups build AI applications meant for millions to use, hiding pre-release testing issues will simply breed mistrust, slow adoption, and frustrate efforts to address risk.
On the other hand, fear-mongering headlines about an evil AI prone to blackmail and deceit is also not terribly useful, if it means that every time we prompt a chatbot we start wondering if it is plotting against us. It makes no difference that the blackmail and deceit came from tests using fictional scenarios that simply helped expose what safety issues needed to be dealt with.
Nathan Lambert, an AI researcher at AI2 Labs, recently pointed out that “the people who need information on the model are people like me—people trying to keep track of the roller coaster ride we’re on so that the technology doesn’t cause major unintended harms to society. We are a minority in the world, but we feel strongly that transparency helps us keep a better understanding of the evolving trajectory of AI.”
We need more transparency, with context
There is no doubt that we need more transparency regarding AI models, not less. But it should be clear that it is not about scaring the public. It’s about making sure researchers, governments, and policy makers have a fighting chance to keep up in keeping the public safe, secure, and free from issues of bias and fairness.
Hiding AI test results won’t keep the public safe. Neither will turning every safety or security issue into a salacious headline about AI gone rogue. We need to hold AI companies accountable for being transparent about what they are doing, while giving the public the tools to understand the context of what’s going on. So far, no one seems to have figured out how to do both. But companies, researchers, the media—all of us—must.
With that, here’s more AI news.
Sharon Goldman
sharon.goldman@fortune.com
@sharongoldman
This story was originally featured on Fortune.com



