
















Researchers at Stanford Propose a Unified Regression-based Machine Learning Framework for Sequence Models with Associative Memory
Sequences are a universal abstraction for representing and processing information, making sequence modeling central to modern deep learning. By framing computational tasks as transformations between sequences, this perspective has extended to diverse fields such as NLP, computer vision, time series analysis, and computational biology. This has driven the development of various sequence models, including transformers, […] The post Researchers at Stanford Propose a Unified Regression-based Machine Learning Framework for Sequence Models with Associative Memory appeared first on MarkTechPost.



Sequences are a universal abstraction for representing and processing information, making sequence modeling central to modern deep learning. By framing computational tasks as transformations between sequences, this perspective has extended to diverse fields such as NLP, computer vision, time series analysis, and computational biology. This has driven the development of various sequence models, including transformers, recurrent networks, and convolutional networks, each excelling in specific contexts. However, these models often arise through fragmented and empirically-driven research, making it difficult to understand their design principles or optimize their performance systematically. The lack of a unified framework and consistent notations further obscures the underlying connections between these architectures.
A key finding linking different sequence models is the relationship between their ability to perform associative recall and their language modeling effectiveness. For instance, studies reveal that transformers use mechanisms like induction heads to store token pairs and predict subsequent tokens. This highlights the significance of associative recall in determining model success. A natural question emerges: how can we intentionally design architectures to excel in associative recall? Addressing this could clarify why some models outperform others and guide the creation of more effective and generalizable sequence models.
Researchers from Stanford University propose a unifying framework that connects sequence models to associative memory through a regression-memory correspondence. They demonstrate that memorizing key-value pairs is equivalent to solving a regression problem at test time, offering a systematic way to design sequence models. By framing architectures as choices of regression objectives, function classes, and optimization algorithms, the framework explains and generalizes linear attention, state-space models, and softmax attention. This approach leverages decades of regression theory, providing a clearer understanding of existing architectures and guiding the development of more powerful, theoretically grounded sequence models.
Sequence modeling aims to map input tokens to output tokens, where associative recall is essential for tasks like in-context learning. Many sequence layers transform inputs into key-value pairs and queries, but the design of layers with associative memory often lacks theoretical grounding. The test-time regression framework addresses this by treating associative memory as solving a regression problem, where a memory map approximates values based on keys. This framework unifies sequence models by framing their design as three choices: assigning weights to associations, selecting the regressor function class, and choosing an optimization method. This systematic approach enables principled architecture design.
To enable effective associative recall, constructing task-specific key-value pairs is critical. Traditional models use linear projections for queries, keys, and values, while recent approaches emphasize “short convolutions” for better performance. A single test-time regression layer with one short convolution is sufficient for solving multi-query associative recall (MQAR) tasks by forming bigram-like key-value pairs. Memory capacity, not sequence length, determines model performance. Linear attention can solve MQAR with orthogonal embeddings, but unweighted recursive least squares (RLS) perform better with larger key-value sets by considering key covariance. These findings highlight the role of memory capacity and key construction in achieving optimal recall.
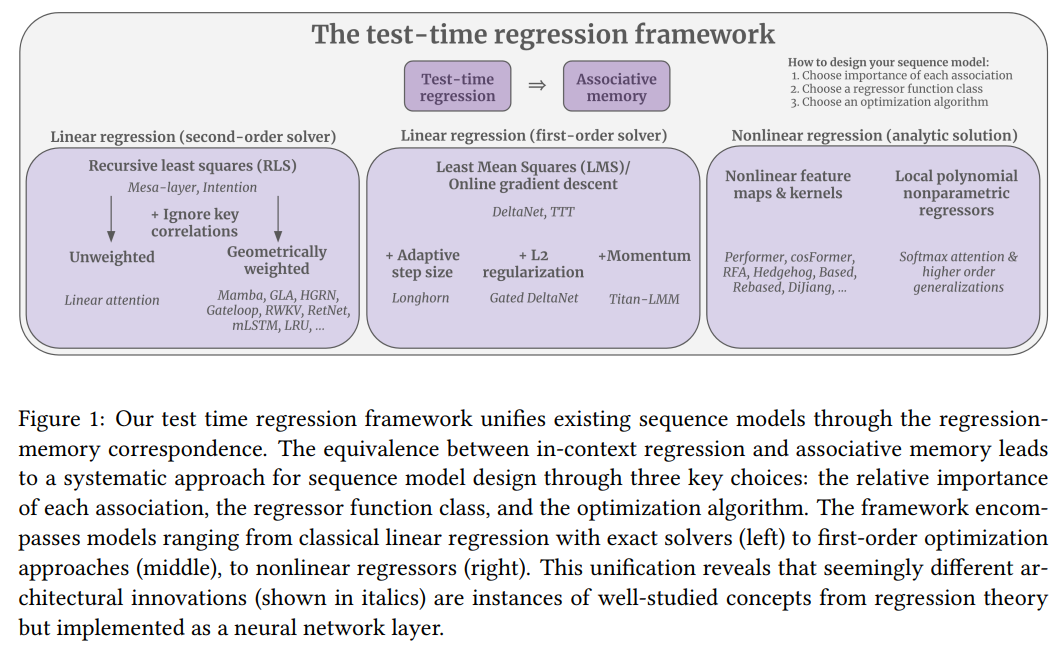
In conclusion, the study presents a unified framework that interprets sequence models with associative memory as test-time regressors, characterized by three components: association importance, regressor function class, and optimization algorithm. It explains architectures like linear attention, softmax attention, and online learners through regression principles, offering insights into features like QKNorm and higher-order attention generalizations. The framework highlights the efficiency of single-layer designs for tasks like MQAR, bypassing redundant layers. By connecting sequence models to regression and optimization literature, this approach opens pathways for future advancements in adaptive and efficient models, emphasizing associative memory’s role in dynamic, real-world environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

What's Your Reaction?














