









![From freeCodeCamp to CTO with Robotics Engineer Peggy Wang [Podcast #159]](https://cdn.hashnode.com/res/hashnode/image/upload/v1738967132406/6ab8c7bb-397a-42b3-bb91-ff9c4842ead0.png?#)























































Process Reinforcement through Implicit Rewards (PRIME): A Scalable Machine Learning Framework for Enhancing Reasoning Capabilities
Reinforcement learning (RL) for large language models (LLMs) has traditionally relied on outcome-based rewards, which provide feedback only on the final output. This sparsity of reward makes it challenging to train models that need multi-step reasoning, like those employed in mathematical problem-solving and programming. Additionally, credit assignment becomes ambiguous, as the model does not get […] The post Process Reinforcement through Implicit Rewards (PRIME): A Scalable Machine Learning Framework for Enhancing Reasoning Capabilities appeared first on MarkTechPost.



Reinforcement learning (RL) for large language models (LLMs) has traditionally relied on outcome-based rewards, which provide feedback only on the final output. This sparsity of reward makes it challenging to train models that need multi-step reasoning, like those employed in mathematical problem-solving and programming. Additionally, credit assignment becomes ambiguous, as the model does not get fine-grained feedback for intermediate steps. Process reward models (PRMs) try to address this by offering dense step-wise rewards, but they need costly human-annotated process labels, making them infeasible for large-scale RL. In addition, static reward functions are plagued by overoptimization and reward hacking, where the model takes advantage of the reward system in unforeseen ways, eventually compromising generalization performance. These limitations restrict RL’s efficiency, scalability, and applicability for LLMs, calling for a new solution that effectively combines dense rewards without high computational expense or human annotations.
Existing RL methods for LLMs mostly employ outcome reward models (ORMs), which offer scores only for the final output. This results in low sample efficiency as models must generate and test whole sequences before getting feedback. Some methods employ value models that estimate future rewards from past actions to counter this. However, these models have high variance and do not properly handle reward sparsity. PRMs offer more fine-grained feedback but need costly manual annotations for intermediate steps and are prone to reward hacking because of static reward functions. Additionally, most existing methods need an extra training phase for the reward model, adding to the computational expense and making them infeasible for scalable online RL.
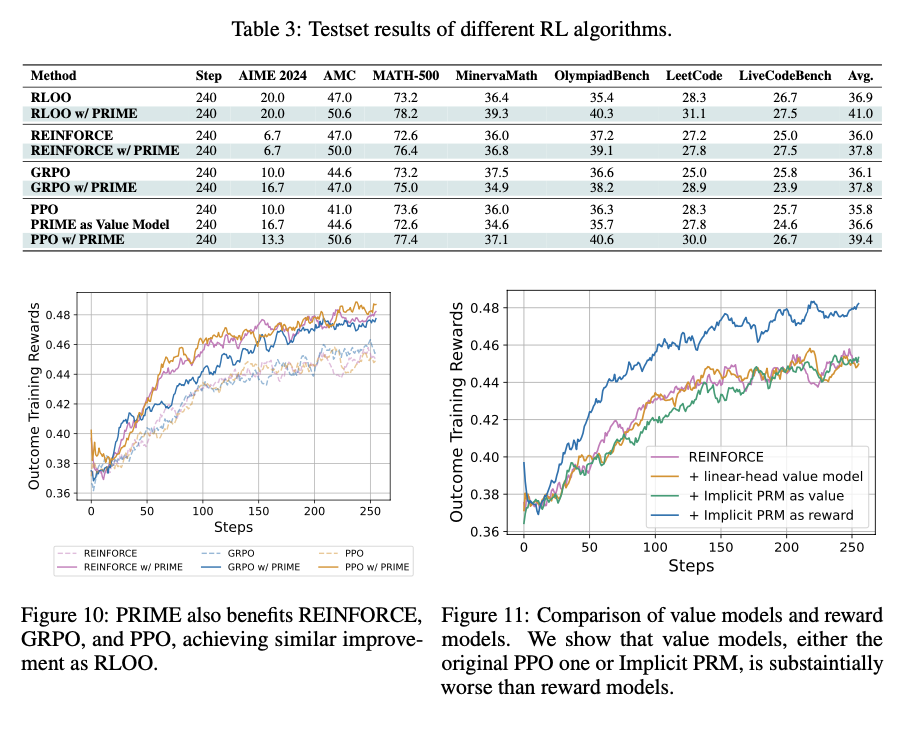
A group of researchers from Tsinghua University, Shanghai AI Lab, University of Illinois Urbana-Champaign, Peking University, Shanghai Jiaotong University, and CUHK has proposed a reinforcement learning framework that eliminates the need for explicit step-wise annotations using efficient utilization of dense feedback. The main contribution proposed is the introduction of an Implicit Process Reward Model (Implicit PRM), which produces token-level rewards independently of outcome labels, thus eliminating the need for human-annotated step-level guidance. The approach allows for continuous online improvement of the reward model, eliminating the problem of overoptimization without allowing dynamic policy rollout adjustments. The framework can successfully integrate implicit process rewards with outcome rewards during advantage estimation, offering computational efficiency and eliminating reward hacking. Unlike previous methods, which require a separate training phase for process rewards, the new approach initializes the PRM directly from the policy model itself, thus greatly eliminating developmental overhead. It is also made compatible with a range of RL algorithms, including REINFORCE, PPO, and GRPO, thus making it generalizable and scalable for training large language models (LLMs).

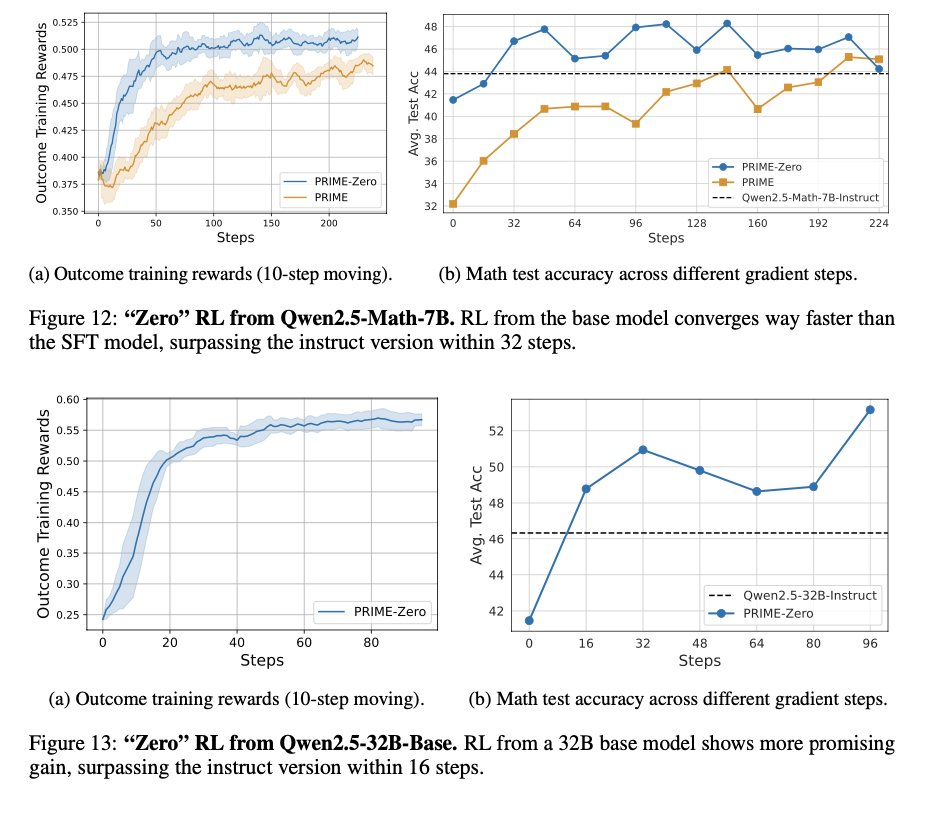
This reinforcement learning system provides token-level implicit process rewards, calculated through a log-ratio formulation between a learned reward model and a reference model. Rather than manual annotation, the reward function is learned from raw outcome labels, which are already obtained for policy training. The system also includes online learning of the reward function to avoid overoptimization and reward hacking. It uses a hybrid advantage estimation approach that combines implicit process and outcome rewards through a leave-one-out Monte Carlo estimator. Policy optimization is achieved through Proximal Policy Optimisation (PPO) using a clipped surrogate loss function for stability. The model was trained using Qwen2.5-Math-7B-Base, an optimized model for mathematical reasoning. The system is based on 150K queries with four samples per query, compared to Qwen2.5-Math-7B-Instruct using 618K in-house annotations, which demonstrates the effectiveness of the training process.
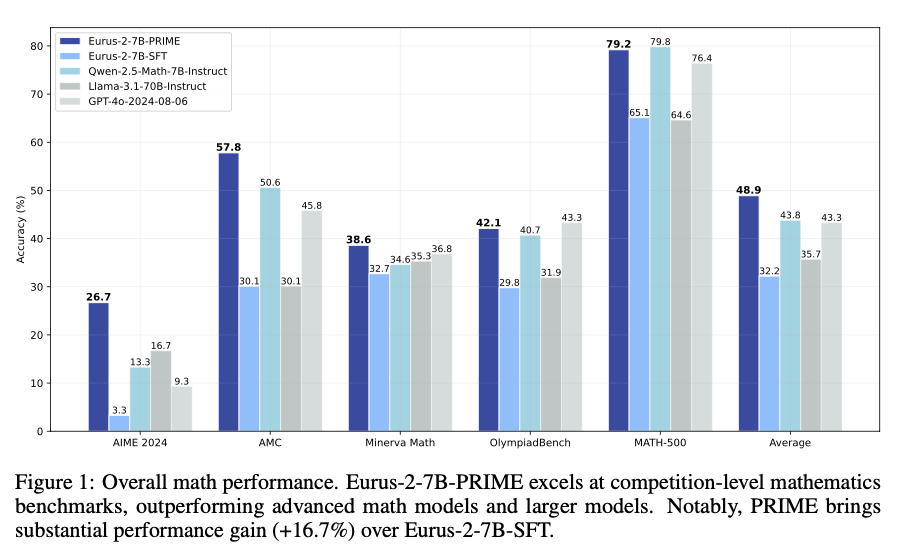
The reinforcement learning system demonstrates significant gains in sample efficiency and reasoning performance across several benchmarks. It provides a 2.5× gain in sample efficiency and a 6.9% gain in mathematical problem-solving compared to standard outcome-based RL. The model outperforms Qwen2.5-Math-7B-Instruct on benchmarking mathematical benchmarks, with better accuracy on competition-level tasks like AIME and AMC. Models trained from this process outperform larger models, including GPT-4o, by pass@1 accuracy for challenging reasoning tasks, even when using only 10% of the training data used by Qwen2.5-Math-7B-Instruct. The results affirm that online updates to the reward model avoid over-optimization, enhance training stability, and enhance credit assignment, making it an extremely powerful method for reinforcement learning in LLMs.
This reinforcement learning approach provides an efficient and scalable LLM training process with dense implicit process rewards. This eliminates step-level explicit annotations and minimizes training costs while enhancing sample efficiency, stability, and performance. The process combines online reward modeling and token-level feedback harmoniously, solving long-standing problems of reward sparsity and credit assignment in RL for LLMs. These improvements optimize reasoning capability in AI models and make them suitable for problem-solving applications in mathematics and programming. This research is a substantial contribution to RL-based LLM training, paving the way for more efficient, scalable, and high-performing AI training approaches.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.









