


































































From Softmax to SSMax: Enhancing Attention and Key Information Retrieval in Transformers
Transformer-based language models process text by analyzing word relationships rather than reading in order. They use attention mechanisms to focus on keywords, but handling longer text is challenging. The Softmax function, which distributes attention, weakens as the input size grows, causing attention fading. This reduces the model’s focus on important words, making it harder to […] The post From Softmax to SSMax: Enhancing Attention and Key Information Retrieval in Transformers appeared first on MarkTechPost.



Transformer-based language models process text by analyzing word relationships rather than reading in order. They use attention mechanisms to focus on keywords, but handling longer text is challenging. The Softmax function, which distributes attention, weakens as the input size grows, causing attention fading. This reduces the model’s focus on important words, making it harder to learn from long texts. As the attention values get smaller, the details become unclear, thus rendering the model ineffective for larger inputs. Unless there is a modification in the attention mechanism, the model does not focus on essential information and, therefore, fails to work well on larger text inputs.
Current methods to improve length generalization in Transformer-based models include positional encoding, sparse attention, extended training on longer texts, and enhanced attention mechanisms. These methods are not scalable and require a lot of computational resources, making them inefficient for handling long inputs. The Softmax function, used in the case of attention distribution in Transformers, degrades as the input size grows. For more tokens, Softmax generates more flat distributions of probabilities that lead to decreasing the emphasis on keywords. Such a phenomenon is known as attention fading, severely limiting the model’s ability to process long text.
To mitigate attention fading in Transformers, a researcher from The University of Tokyo proposed Scalable-Softmax (SSMax), which modifies the Softmax function to maintain attention on important tokens even when the input size increases. Unlike Softmax, which causes attention to spread thinly as the input grows, SSMax adjusts the scaling factor based on the input size, ensuring that the highest value remains dominant. This avoids loss of focus on key information in larger contexts. This framework incorporates a scaling factor that involves the size of the input, which alters the formula for calculating attention by using a logarithm. The model dynamically adapts to concentrate on relevant elements when variations apply and distributes attention when similar values are used. SSMax integrates easily into existing architectures with minimal changes, requiring only a simple multiplication in the attention computation.
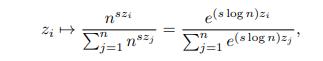
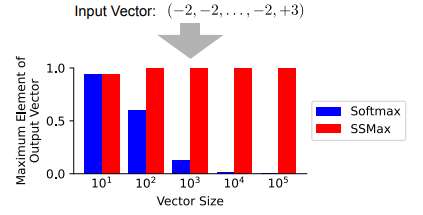
To evaluate the impact of replacing Softmax with Scalable-Softmax (SSMax) in attention layers, the researcher conducted experiments on training efficiency, long-context generalization, key information retrieval, and attention allocation. They tested six configurations, including standard Softmax, SSMax with and without a scaling parameter, SSMax with a bias parameter, and two models where Softmax was replaced with SSMax after or during pretraining. SSMax consistently improved training efficiency and long-context generalization, reducing test loss across extended sequence lengths. The Needle-In-A-Haystack test revealed that SSMax significantly enhanced key information retrieval in long contexts. However, removing the scaling parameter or adding a bias degraded performance. Models where Softmax was replaced with SSMax post-training or late in pretraining, showed partial improvements but failed to match fully trained SSMax models.
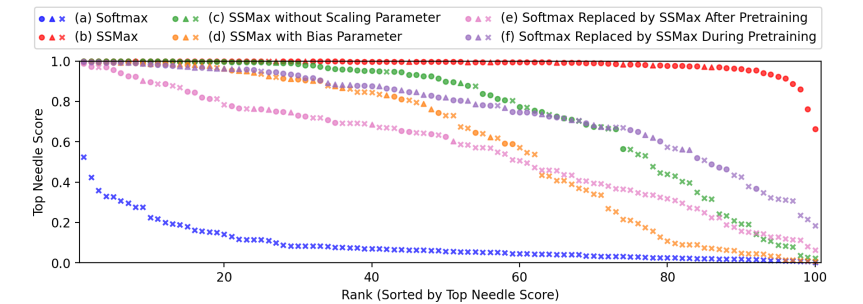
In summary, this proposed method improved transformer attention, which defeats attention fading and strengthens length generalization, making models more effective in long-context tasks. Its adaptability benefited newly trained and existing models, positioning it as a strong alternative to Softmax. The future can optimize SSMax for efficiency and integrate it into emerging Transformer models to enhance long-context understanding in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.









