


















ByteDance Researchers Introduce PaSa: An Advanced Paper Search Agent Powered by Large Language Models
Academic paper search represents a critical yet intricate information retrieval challenge within research ecosystems. Researchers require complex search capabilities that can navigate complex, specialized knowledge domains and address nuanced, fine-grained queries. Current academic search platforms like Google Scholar struggle to handle intricate research-specific investigations. For example, specialized query-seeking studies on non-stationary reinforcement learning (RL) using […] The post ByteDance Researchers Introduce PaSa: An Advanced Paper Search Agent Powered by Large Language Models appeared first on MarkTechPost.



Academic paper search represents a critical yet intricate information retrieval challenge within research ecosystems. Researchers require complex search capabilities that can navigate complex, specialized knowledge domains and address nuanced, fine-grained queries. Current academic search platforms like Google Scholar struggle to handle intricate research-specific investigations. For example, specialized query-seeking studies on non-stationary reinforcement learning (RL) using UCB-based value methods demand extensive computational and analytical capabilities. Moreover, Researchers often invest considerable time and effort in conducting comprehensive literature surveys, and manually navigating through extensive academic databases.
Existing research methodologies for academic paper search and scientific discovery have explored various applications of LLMs across different research stages. Researchers have utilized LLMs for diverse tasks including idea generation, experiment design, code writing, and research paper creation. However, traditional tools like Google Scholar remain inadequate for handling complex, specialized research queries. Many works have focused on developing LLM agents through prompt engineering techniques and optimization frameworks. Notably, approaches like the AGILE RL framework have emerged to enable more comprehensive and adaptive agent skills. Despite these advancements, a detailed solution for autonomous and precise academic paper searches remains unaddressed, creating a significant research gap.
Researchers from ByteDance Research, and Peking University have proposed PaSa, an innovative paper search agent powered by LLMs. PaSa represents a complex approach to academic research, capable of autonomously executing complex search strategies including tool invocation, paper reading, and reference selection. The agent is designed to generate comprehensive and precise results for intricate scholarly queries. To optimize PaSa’s performance, researchers develop AutoScholarQuery, a synthetic dataset comprising 35k fine-grained academic queries from top-tier AI conference publications. They created RealScholarQuery, a benchmark for evaluating the agent’s real-world performance. The novel approach utilizes RL techniques to enhance the agent’s search capabilities, addressing significant limitations in existing academic search methodologies.
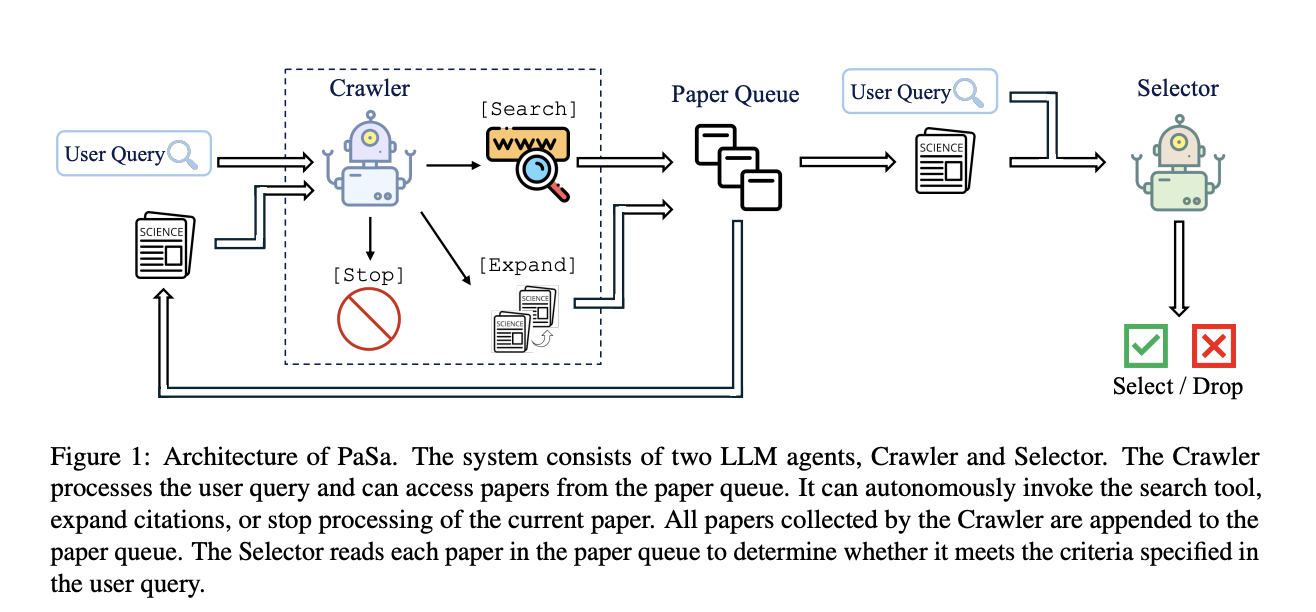
The PaSa system comprises two LLM agents: the Crawler and the Selector, working collaboratively to execute comprehensive academic paper searches. The Crawler initiates the process by analyzing the user’s query to generate multiple refined search queries to retrieve relevant papers. These retrieved papers are added to a dedicated paper queue. The Crawler processes each queued paper, identifying and exploring key citations that might expand the research scope, dynamically appending newly discovered relevant papers, to the paper list. Further, a review is conducted by the Selector of each paper, evaluating its alignment with the original query requirements. The training process for the Crawler involves a two-stage approach: initial imitation learning on a subset of training data, followed by RL optimization.
The experimental results demonstrate PaSa-7b’s superior performance across multiple benchmarks. On the AutoScholarQuery test set, PaSa-7b outperforms existing baselines, achieving a 9.64% improvement in recall compared to PaSa-GPT-4o while maintaining comparable precision. PaSa-7b exhibits remarkable gains against Google-based baselines, with improvements ranging from 33.80% to 42.64% across different recall metrics. Moreover, using multiple Crawler ensembles during inference enhances performance, increasing crawler recall by 3.34% and overall system recall by 1.51%. In the more challenging RealScholarQuery scenario, PaSa-7b demonstrates even more pronounced advantages, delivering 30.36% higher recall and 4.25% improved precision compared to PaSa-GPT-4o.
In conclusion, researchers introduced PaSa which represents an advancement in academic paper search technologies, addressing critical challenges in information retrieval for scholarly research. By utilizing LLMs and RL techniques, the PaSa offers a detailed solution to the complex task of identifying and retrieving relevant academic papers. The proposed method demonstrates substantial improvements over existing search methodologies, significantly reducing the time and effort, researchers spend on literature reviews. Moreover, PaSa provides researchers with a powerful tool for navigating the increasingly vast and complex landscape of academic literature. Its ability to autonomously generate, search, and evaluate academic papers marks a significant step forward in scientific information retrieval.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

What's Your Reaction?














