.png)





















![‘Companion’ Ending Breakdown: Director Drew Hancock Tells All About the Film’s Showdown and Potential Sequel: ‘That’s the Future I Want for [Spoiler]’](https://variety.com/wp-content/uploads/2025/02/MCDCOMP_WB028.jpg?#)













An In-Depth Exploration of Reasoning and Decision-Making in Agentic AI: How Reinforcement Learning RL and LLM-based Strategies Empower Autonomous Systems
Agentic AI gains much value from the capacity to reason about complex environments and make informed decisions with minimal human input. The first article of this five-part series focused on how agents perceive their surroundings and store relevant knowledge. This second article explores how that input and context are transformed into purposeful actions. The Reasoning/Decision-Making […] The post An In-Depth Exploration of Reasoning and Decision-Making in Agentic AI: How Reinforcement Learning RL and LLM-based Strategies Empower Autonomous Systems appeared first on MarkTechPost.



Agentic AI gains much value from the capacity to reason about complex environments and make informed decisions with minimal human input. The first article of this five-part series focused on how agents perceive their surroundings and store relevant knowledge. This second article explores how that input and context are transformed into purposeful actions. The Reasoning/Decision-Making Module is the system’s dynamic “mind,” guiding autonomous behavior across diverse domains, from conversation-based assistants to robotic platforms navigating physical spaces.
This module can be viewed as the bridge between observed reality and the agent’s objectives. It takes preprocessed signals, images turned into feature vectors, text converted into embeddings, sensor readings filtered for noise, and consults existing knowledge to interpret the current situation. Based on that interpretation, it projects hypothetical outcomes of possible actions and selects one that best aligns with its goals, constraints, or rules. In short, it closes the feedback loop that begins with raw perception and ends with real-world or digital execution.
Reasoning and Decision-Making in Context
In everyday life, humans integrate learned knowledge and immediate observations to make decisions, from trivial choices like selecting a meal to high-stakes considerations such as steering a car to avoid an accident. Agentic AI aims to replicate, and sometimes exceed, this adaptive capability by weaving together multiple computational strategies under a unified framework. Traditional rule-based systems, known for their explicit logical structure, can handle well-defined problems and constraints but often falter in dynamic contexts where new and unexpected scenarios arise. Machine learning, by contrast, provides flexibility and can learn from data, but in certain situations, it may offer less transparency or guarantee of correctness.
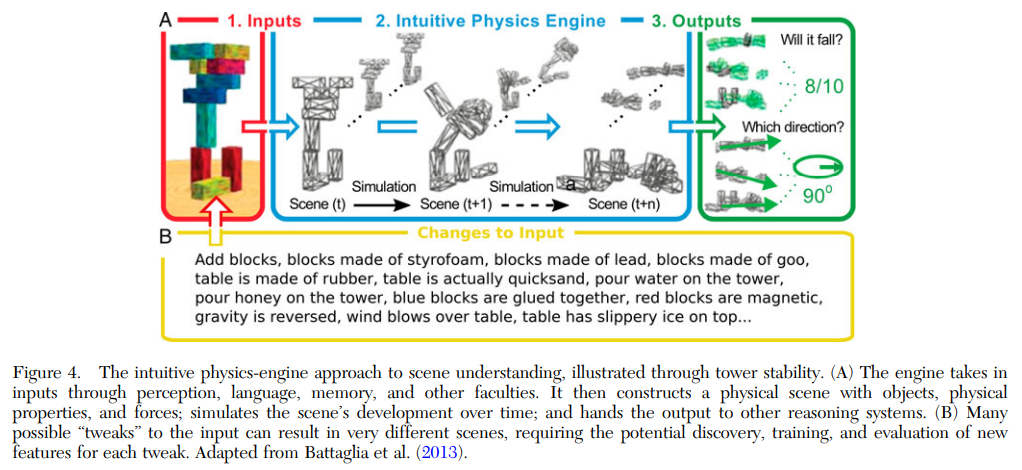
Agentic AI unites these approaches. Reinforcement learning (RL) can teach an agent to refine its behavior over time by interacting with an environment, maximizing rewards that measure success. Meanwhile, large language models (LLMs) such as GPT-4 add a new dimension by allowing agents to use conversation-like steps, sometimes called chain-of-thought reasoning, to interpret intricate instructions or ambiguous tasks. Combined, these methods produce a system that can respond robustly to unforeseen situations while adhering to basic rules and constraints.
Classical vs. Modern Approaches
Classical Symbolic Reasoning
Historically, AI researchers focused heavily on symbolic reasoning, where knowledge is encoded as rules or facts in a symbolic language. Systems like expert shells and rule-based engines parse these symbols and apply logical inference (forward chaining, backward chaining) to arrive at conclusions.
- Strengths: High interpretability, deterministic behavior, and ease of integrating strict domain knowledge.
- Limitations: Difficulty handling uncertainty, scalability challenges, and brittleness when faced with unexpected inputs or scenarios.
Symbolic reasoning can still be very effective for certain narrowly defined tasks, such as diagnosing a well-understood technical issue in a controlled environment. However, the unpredictable nature of real-world data, coupled with the sheer diversity of tasks, has led to a shift toward more flexible and robust frameworks, particularly reinforcement learning and neural network-based approaches.
RL is a powerful paradigm for decision-making in uncertain, dynamic environments. Unlike supervised learning, which relies on labeled examples, RL agents learn by engaging with an environment and optimizing a reward signal. Some of the most prominent RL algorithms include:
- Q-Learning: Agents learn a value function Q(s, a), where s – state and a – action. This function estimates the future cumulative reward for taking action a in state s and following a particular policy. The agent refines these Q-values through repeated exploration, gradually converging to a policy that maximizes long-term rewards.
- Policy Gradients: In place of learning a value function, policy gradient methods directly adjust the parameters of a policy function