
































































4 Things I Learned Building a Data Platform using a Medallion Architecture in the Last 4 Years
4 Things I Learned Building a Data Platform using Medallion Architecture in the Last 4 YearsLessons learned from a data platform in a production environmentPhoto by Unsplash+ Community on UnsplashThis month, I celebrated four years of working on a big data platform that uses the medallion architecture for data organization. All my previous experiences were linked to different data organization approaches. Therefore, considering this milestone, I decided to share some lessons I’ve learned along the way, which I believe may be helpful to others working with a similar approach.First… some context: What is the medallion architecture?In summary, it is a design pattern in the data domain meant for logical data organization within a lakehouse. The goal is to progressively improve the data structure and quality through the layers defined in the design pattern (bronze, silver, gold). In summary:Bronze layer: Raw data. This is the landing zone where the ingested data arrives. There are no data transformations at this level.Silver layer: Here, you can apply simple cleanings to your raw data and store it in this layer. A defined schema and data types are expected.Gold layer: This layer represents your consumption layer. It is the place for complex aggregations, joins, and business logic. The platform’s users consider it the place to go when running their data queries.The following diagram illustrates this concept and is most likely self-explanatory:Image by AuthorIf you want to learn more about this topic, I can refer you to these links:What is a Medallion Architecture?Using a medallion architecture for lakehouse dataNow, let’s talk about the lessons learned!All right, conceptually speaking, everything is beautiful, but when the daily routines arrives, we should sometimes be flexible and elaborate on the best solution for the specific situation in our business.So, these are the 4 takeaways that I want to share based on my last 4 years of experience in this topic:#1 Don’t be orthodox applying the medallion architectureAs you can see in the references, the official documentation outlines a few key steps for applying the medallion architecture. For example: no schema is needed in the bronze layer, or even only minimal data cleaning is indicated in the silver layer. However, depending on your demands, you should be confident in making some adjustments based on our project’s business reality.In my experience, there have been several instances where we had to adapt the guidelines to achieve the best outcomes. I can share the following:We have data schemas for all the layers, including the bronze layer, in the data platform. As we interact with different data sources (such as EventHubs, CSV files, Oracle connections, and others), schema enforcement has been adopted to ensure that any non-expected changes in the data sources and their data contracts are detected and addressed promptly, preventing disruptions to downstream processes.#2 New layers, why not?This one is a bit connected with the item above, but it needs a specific section since it may be disruptive for some people. The point here is that, in some cases, it is better to define your own specific data layer than try to figure out what the ideal layer in the design by the book would be.I am pretty confident that if you worked on the medallion architecture, you already questioned yourself about the layers’ purpose and where you should locate certain data after a couple of transformations (leave it in silver? Move it to gold?).Over the past years, we have arrived at a point where:Our project data organization includes layers such as ‘Reference’, ‘Sandbox’, and ‘Checkpoints’, among others. These layers were introduced to address the need for precise data location in some instances. For example, the ‘Reference’ layer was created to store lookup data. This clear separation ensures that everyone on the team knows exactly where to find and add lookup data, eliminating any confusion between the silver and gold layers.#3 Mappings in the catalog toolYou’re likely using a data catalog tool. In my current project, we use Unity Catalog for data governance, requiring us to map our external storage locations (aligned with the medallion architecture) to the catalog. This mapping requires careful consideration.Since there are no strict constraints between schema names and storage roots, it’s crucial to avoid mismatches. For example, mapping a bronze table to a silver schema or any other confusing configuration can lead to misinterpretations and errors.In our specific case, we have different permission sets for Personally Identifiable Information (PII) and non-PII data. To manage this within the catalog, we mapped both PII and non-PII data to the same silver layer but differentiated them by placing them in two separate schemas. This approach allows us to maintain the logical grouping of the silver layer while enforcing granular access control based on data sensitivity.Image by Author#4

4 Things I Learned Building a Data Platform using Medallion Architecture in the Last 4 Years
Lessons learned from a data platform in a production environment
This month, I celebrated four years of working on a big data platform that uses the medallion architecture for data organization. All my previous experiences were linked to different data organization approaches. Therefore, considering this milestone, I decided to share some lessons I’ve learned along the way, which I believe may be helpful to others working with a similar approach.
First… some context: What is the medallion architecture?
In summary, it is a design pattern in the data domain meant for logical data organization within a lakehouse. The goal is to progressively improve the data structure and quality through the layers defined in the design pattern (bronze, silver, gold). In summary:
- Bronze layer: Raw data. This is the landing zone where the ingested data arrives. There are no data transformations at this level.
- Silver layer: Here, you can apply simple cleanings to your raw data and store it in this layer. A defined schema and data types are expected.
- Gold layer: This layer represents your consumption layer. It is the place for complex aggregations, joins, and business logic. The platform’s users consider it the place to go when running their data queries.
The following diagram illustrates this concept and is most likely self-explanatory: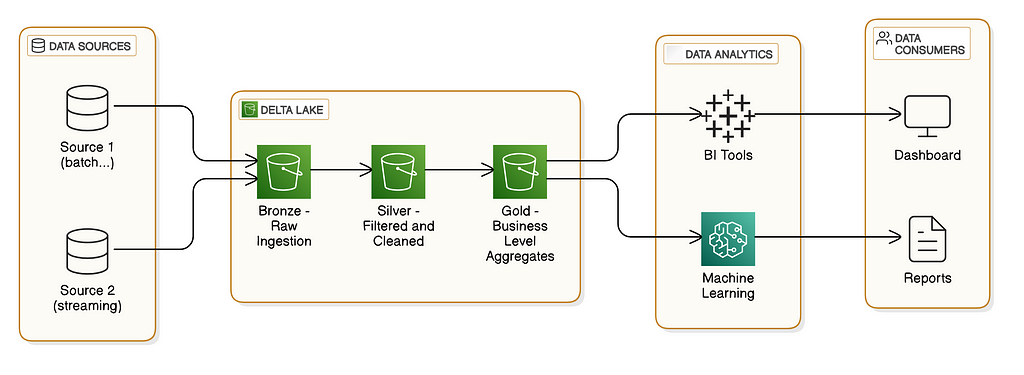
If you want to learn more about this topic, I can refer you to these links:
Now, let’s talk about the lessons learned!
All right, conceptually speaking, everything is beautiful, but when the daily routines arrives, we should sometimes be flexible and elaborate on the best solution for the specific situation in our business.
So, these are the 4 takeaways that I want to share based on my last 4 years of experience in this topic:
#1 Don’t be orthodox applying the medallion architecture
As you can see in the references, the official documentation outlines a few key steps for applying the medallion architecture. For example: no schema is needed in the bronze layer, or even only minimal data cleaning is indicated in the silver layer. However, depending on your demands, you should be confident in making some adjustments based on our project’s business reality.
In my experience, there have been several instances where we had to adapt the guidelines to achieve the best outcomes. I can share the following:
- We have data schemas for all the layers, including the bronze layer, in the data platform. As we interact with different data sources (such as EventHubs, CSV files, Oracle connections, and others), schema enforcement has been adopted to ensure that any non-expected changes in the data sources and their data contracts are detected and addressed promptly, preventing disruptions to downstream processes.
#2 New layers, why not?
This one is a bit connected with the item above, but it needs a specific section since it may be disruptive for some people. The point here is that, in some cases, it is better to define your own specific data layer than try to figure out what the ideal layer in the design by the book would be.
I am pretty confident that if you worked on the medallion architecture, you already questioned yourself about the layers’ purpose and where you should locate certain data after a couple of transformations (leave it in silver? Move it to gold?).
Over the past years, we have arrived at a point where:
- Our project data organization includes layers such as ‘Reference’, ‘Sandbox’, and ‘Checkpoints’, among others. These layers were introduced to address the need for precise data location in some instances. For example, the ‘Reference’ layer was created to store lookup data. This clear separation ensures that everyone on the team knows exactly where to find and add lookup data, eliminating any confusion between the silver and gold layers.
#3 Mappings in the catalog tool
You’re likely using a data catalog tool. In my current project, we use Unity Catalog for data governance, requiring us to map our external storage locations (aligned with the medallion architecture) to the catalog. This mapping requires careful consideration.
Since there are no strict constraints between schema names and storage roots, it’s crucial to avoid mismatches. For example, mapping a bronze table to a silver schema or any other confusing configuration can lead to misinterpretations and errors.
- In our specific case, we have different permission sets for Personally Identifiable Information (PII) and non-PII data. To manage this within the catalog, we mapped both PII and non-PII data to the same silver layer but differentiated them by placing them in two separate schemas. This approach allows us to maintain the logical grouping of the silver layer while enforcing granular access control based on data sensitivity.

#4 Flexible but not a mess
Although I’ve just mentioned that you might feel confident making transformations in various layers or even adding new ones, we should be cautious not to completely reconfigure the design pattern, as this could make maintenance significantly more difficult.
The key is that the underlying medallion Architecture should remain recognizable even with the modifications. For example, a new team member should easily understand the data flow and recognize the established design pattern. This consistency is crucial for long-term maintainability.
Additionally, be careful when mixing different data concepts such as data mesh, data vault, data warehouse, and others as you set up your data organization. Consider how these concepts integrate with your medallion Architecture rather than being implemented within it.
Final Thoughts
I hope this is useful to you in some way. If you’ve made it this far, I genuinely appreciate your attention and encourage you to share your thoughts in the comments section. :)
See you!
4 Things I Learned Building a Data Platform using a Medallion Architecture in the Last 4 Years was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.







