
















































Коллекция бесплатных датасетов для обучения моделей
Недавно мы опубликовали подборку онлайн-курсов по машинному обучению, а в этом посте мы собрали подборку ресурсов, из которых вы сможете выбрать подходящие данные для своих проектов по машинному обучению, анализу данных и визуализации.Работая с датасетами, важно учитывать их структуру, объем и качество данных. Хорошо подготовленный датасет может значительно упростить обучение модели и повысить точность прогнозов.Бесплатные датасеты1. Kaggle Datasets — огромная коллекция датасетов для задач машинного обучения, анализа данных и визуализации. Здесь вы найдете как классические наборы данных (например, Titanic или MNIST), так и необычные, такие как данные по сериалу «Игра престолов» или статистика футбольных матчей.2. Awesome Public Datasets — GitHub-репозиторий с огромным списком бесплатных датасетов на все случаи жизни. Здесь вы найдете данные по здравоохранению, финансам, географии, а также редкие специализированные наборы для узких исследований. Отличный ресурс для вдохновения и поиска необычных датасетов.3. UCI Machine Learning Repository — классический источник датасетов для исследований и экспериментов. Этот репозиторий существует уже много лет и содержит сотни датасетов для задач классификации, регрессии и кластеризации. Отличный выбор для тестирования новых алгоритмов.4. Google Dataset Search — поисковик от Google, который помогает находить открытые датасеты по любым темам: от научных исследований до социальных и экономических данных. Удобный инструмент для быстрого поиска нужной информации.5. Hugging Face Datasets — библиотека от платформы Hugging Face, где собраны датасеты для задач обработки естественного языка (NLP), компьютерного зрения и машинного обучения. Поддерживает удобную интеграцию с моделями и фреймворками для обучения ИИ.6. Azure Open Datasets — коллекция открытых датасетов от Microsoft Azure. Здесь вы найдете данные для задач в области здравоохранения, финансов, демографии, транспорта и многого другого. Отлично подходит для использования в облачных проектах и при работе с большими данными.7. Registry of Open Data on AWS — реестр открытых данных на платформе Amazon Web Services (AWS). Включает датасеты для анализа изображений, работы с текстами, биоинформатики, данных о климате и многого другого. Удобен для использования в облачных вычислениях. Использование готовых датасетов экономит время и позволяет сосредоточиться на анализе и построении моделей, а не на сборе данных. Это также помогает новичкам быстрее погружаться в практику машинного обучения, работая с реальными данными.
Недавно мы опубликовали подборку онлайн-курсов по машинному обучению, а в этом посте мы собрали подборку ресурсов, из которых вы сможете выбрать подходящие данные для своих проектов по машинному обучению, анализу данных и визуализации.
Работая с датасетами, важно учитывать их структуру, объем и качество данных. Хорошо подготовленный датасет может значительно упростить обучение модели и повысить точность прогнозов.
Бесплатные датасеты
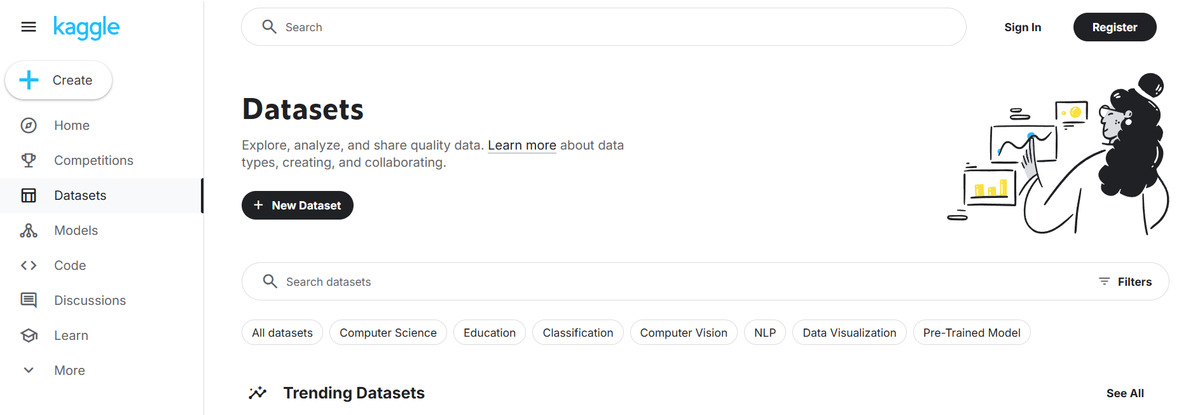
1. Kaggle Datasets — огромная коллекция датасетов для задач машинного обучения, анализа данных и визуализации. Здесь вы найдете как классические наборы данных (например, Titanic или MNIST), так и необычные, такие как данные по сериалу «Игра престолов» или статистика футбольных матчей.
2. Awesome Public Datasets — GitHub-репозиторий с огромным списком бесплатных датасетов на все случаи жизни. Здесь вы найдете данные по здравоохранению, финансам, географии, а также редкие специализированные наборы для узких исследований. Отличный ресурс для вдохновения и поиска необычных датасетов.
3. UCI Machine Learning Repository — классический источник датасетов для исследований и экспериментов. Этот репозиторий существует уже много лет и содержит сотни датасетов для задач классификации, регрессии и кластеризации. Отличный выбор для тестирования новых алгоритмов.
4. Google Dataset Search — поисковик от Google, который помогает находить открытые датасеты по любым темам: от научных исследований до социальных и экономических данных. Удобный инструмент для быстрого поиска нужной информации.
5. Hugging Face Datasets — библиотека от платформы Hugging Face, где собраны датасеты для задач обработки естественного языка (NLP), компьютерного зрения и машинного обучения. Поддерживает удобную интеграцию с моделями и фреймворками для обучения ИИ.
6. Azure Open Datasets — коллекция открытых датасетов от Microsoft Azure. Здесь вы найдете данные для задач в области здравоохранения, финансов, демографии, транспорта и многого другого. Отлично подходит для использования в облачных проектах и при работе с большими данными.
7. Registry of Open Data on AWS — реестр открытых данных на платформе Amazon Web Services (AWS). Включает датасеты для анализа изображений, работы с текстами, биоинформатики, данных о климате и многого другого. Удобен для использования в облачных вычислениях.

Использование готовых датасетов экономит время и позволяет сосредоточиться на анализе и построении моделей, а не на сборе данных. Это также помогает новичкам быстрее погружаться в практику машинного обучения, работая с реальными данными.